Multi-Agent AI Is Slower, Costlier, and Sometimes Finds Better Answers
I built three AI agents to plan a trip and raced them against one. Here's what I learned about cost, speed, and answer quality.
Disclaimer: The views expressed here are my own and are not related to or reflective of my work or any organization I am affiliated with.
The premise came from a research paper. “The Orchestration of Multi-Agent Systems” provides a framework for building coordinated AI systems, and it cites a motivating claim: distributed collectives of smaller, specialized agents often outperform a single all-purpose deployment. Instead of one AI doing everything, you break the problem into parts, give each part to a specialist, and coordinate them through an orchestrator.
It sounds right. The way a hospital works. The way an engineering team works. Specialization plus coordination equals better outcomes.
But sounding right is not the same as being right.
So I tested it.
Three agents. One finds flights and hotels. One builds the itinerary. One tracks the budget. A deterministic Python orchestrator coordinates them, enforces budget gates, and controls what each agent can see. Real flight prices from web search, not training data. About 1,500 lines of Python, no frameworks, every design decision visible. The point was to understand orchestration by building it.
The paper formalizes orchestration as seven responsibilities planning, policy, execution, control, state, knowledge, and quality, each mapping to a method or component in the code. The five most important:
class Orchestrator:
def plan(self, goal) -> list[Task]: # Pi: decompose the goal
def check_policy(self, category, price): # Phi: enforce constraints
def _execute_task(self, task, agents): # E: dispatch to agents
def _prefetch_search_data(self): # K: fetch real prices
def _assemble_plan(self) -> TripPlan: # Q: validate and assembleThe most important design decision is what each agent can see. One shared notebook, three different windows into it. The notebook is a Pydantic model with a get_view method the paper’s observation function that returns a typed dataclass per agent.
class SharedNotebook:
def get_view(self, agent_name) -> ScoutView | PlannerView | BudgetView:
if agent_name == "scout":
return ScoutView(
budget_limits=..., # flight/hotel/activity ceilings
flight_search_results=..., # raw search data
hotel_search_results=...,
) # does NOT include: itinerary, decisions, other agents' outputs
elif agent_name == "planner":
return PlannerView(
confirmed_bookings=..., # only APPROVED decisions
per_day_budget=..., # remaining ÷ days
attraction_search_results=...,
) # does NOT include: rejected options, raw prices
elif agent_name == "budget":
return BudgetView(
all_prices=..., # every price from every source
running_total=...,
budget_ceiling=...,
) # does NOT include: activity names, preferences
else:
raise ValueError(f"Unknown agent: {agent_name}")Scout never sees what the Planner decided. Budget never sees which temples were chosen. Each agent gets only what it needs to do its job.
Then I built a single-agent version. Same model, same search data, same instructions. One prompt that does everything at once. I ran both systems across three cities (Tokyo, Paris, Bangkok), two runs each, and compared what they found.
The sample size is small. Two runs per city gives you direction, not proof. But the patterns were consistent enough to be worth sharing.
The single agent was faster every time. About 100 seconds versus 130. It used fewer tokens. About 10,000 versus 14,500. On pure efficiency, the generalist wins.
But then I looked at the flight prices.
For Paris, both systems found the same $1,199 flight. Dead tie, both runs. The SFO to Paris route has limited options. When the answer is obvious, specialization adds nothing.
For Tokyo, the single agent found cheaper flights. $946 average versus $1,144. Multi-agent is not always better. My read on why: Tokyo is a well-known route with a moderate number of carriers. The search results contained enough information for a generalist to find the best option without deep analysis. But the multi-agent system’s rigid pipeline introduced information loss at each handoff. Specifically, a method called _approve_best_options picks flights[0] from Scout’s sorted list and marks everything else as rejected before Budget ever sees the alternatives. The orchestrator pre-decides the winner. Call it the Lossy Handover problem: if your orchestrator is too rigid, it dumbs down the specialists. The single agent saw everything at once and acted as its own soft orchestrator, weighing all options simultaneously. Structure helped in Bangkok. In Tokyo, it got in the way.
For Bangkok, the multi-agent system found flights at $293. The single agent picked $885. Consistent across both runs. A $592 difference on a $1,500 budget trip. (All prices are search-reported via Tavily, not verified bookings. The exact numbers will differ if you run this tomorrow. What matters is the gap and what caused it.)
Bangkok has dozens of carriers, multiple layover options through Asian hubs, and a wide spread of price points. When Scout’s only job is analyzing flight options, it digs deeper. It found a route the single agent missed entirely. The single agent was juggling flights, hotels, itinerary, and budget at the same time. It picked a reasonable option and moved on.
That is the pattern.
Here is the data across all six runs:
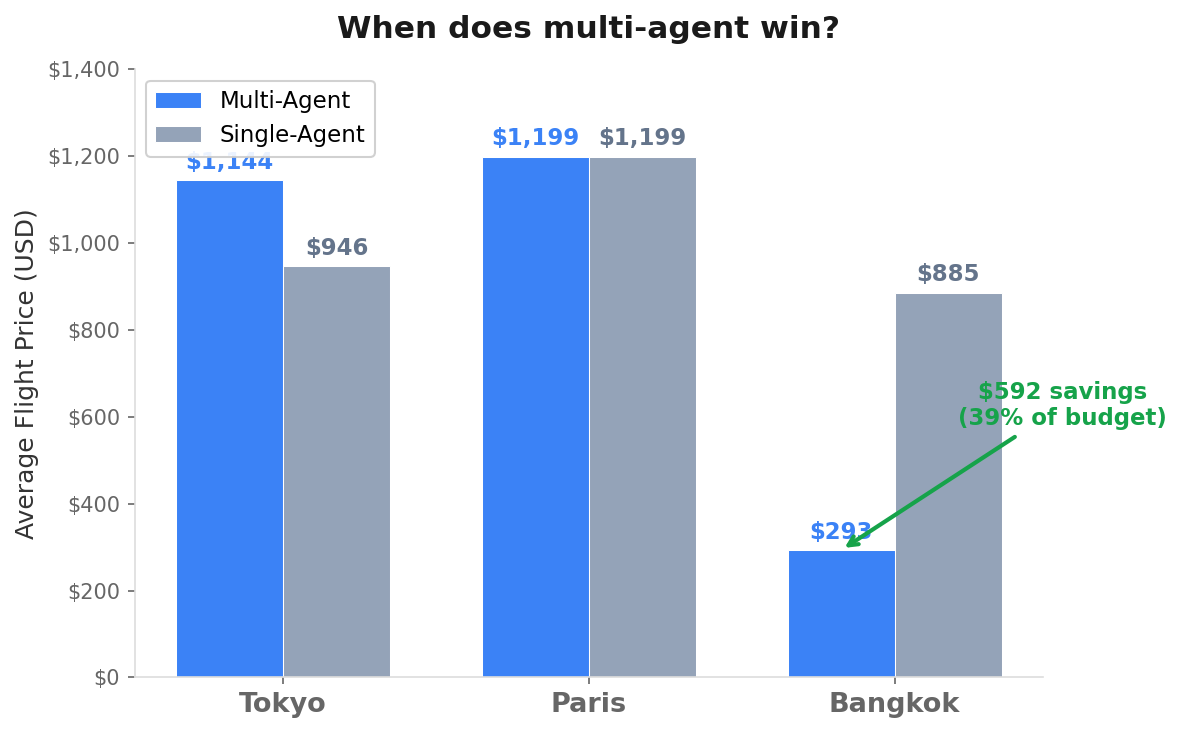
Averages across two runs per city. All prices from Tavily web search, not verified bookings.
The multi-agent system used 40-50% more tokens every time. It was slower every time. But for Bangkok it saved $592 on a $1,500 trip. The token overhead cost maybe fifty cents.
It is not about task complexity in the abstract. It is about search space. When there are many valid options spread across a large space, a specialist who does nothing but search will find things a generalist misses. When the answer is obvious or the space is small, the overhead is not worth it.
There were other findings worth noting.
Restricting what each agent can see (what multi-agent theory calls the observation function) reduces context size substantially. Budget does not need to process itinerary descriptions. Scout does not need to see rejected options. Less context, smaller prompts, lower cost. I did not run a controlled experiment isolating this variable, but the multi-agent token counts (averaging around 14,500 across all runs) are spread across four sequential calls, each with a focused prompt. A single prompt carrying all the context for all three roles would be larger than any one of them.
But the cost savings is not the most interesting part. The observation function is also a least-privilege boundary. Budget cannot see which temples were chosen or what the traveler’s personal interests are. It sees prices. That is all it needs and all it should have. In a system where agents might be backed by different models, different providers, or different trust levels, controlling what each agent can see is not just an optimization. It is a security and privacy decision. The same pattern that reduces token cost also enforces data isolation.
Here is how state flows through the system.
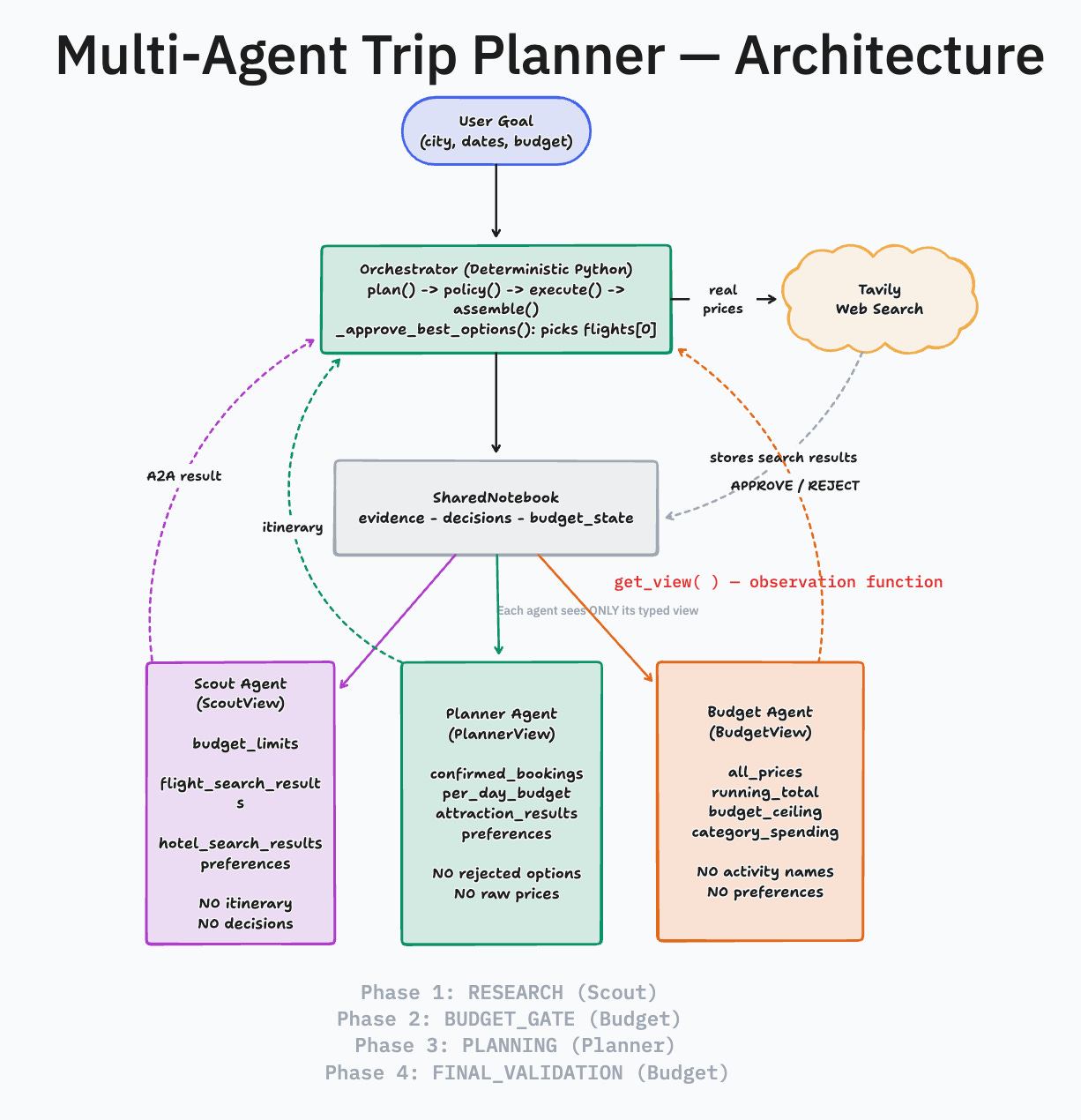
A note on the plumbing. The paper specifies two protocols underneath the diagram above. MCP (Model Context Protocol) controls tool access: only the orchestrator calls MCP servers, and agents only analyze data that was pre-fetched for them. A2A (Agent-to-Agent) is the message schema. Every inter-agent communication is a typed Pydantic model with a
message_type(TASK_ASSIGN, APPROVE, REJECT), a confidence score, and a provenance chain. When Budget flags a flight, it returns a structured REJECT with confidence 0.95 and a list of reasons, not free text. That structure is what lets the orchestrator make deterministic decisions instead of parsing natural language.
I tested this directly. I injected a fake “$200 SCAM Air 999” flight into the search results for a Tokyo trip where real flights cost $800-1,200. The Budget agent flagged it with three warnings: the price was unrealistic for the route, the spending was near category limits, and the carrier name was suspicious. A specialist whose only job is checking numbers catches things a generalist might miss while multitasking. Interestingly, even the single agent did not use the scam price; the LLM had its own sense of realistic pricing. But the multi-agent system caught it earlier, at the budget gate, before it could reach the Planner at all. Defense in depth.
The paper warns about coordination overhead. I measured it directly in a head-to-head run on the same Tokyo trip:
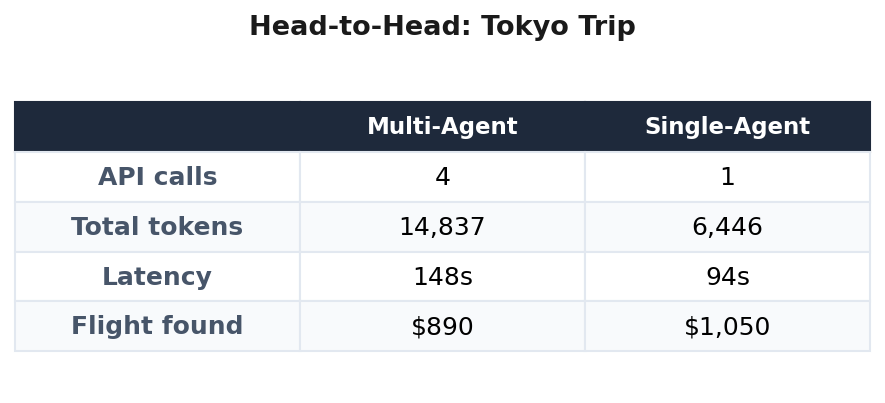
The real cost is not in the messages between agents. It is in the latency of four sequential API calls and the context window space used to give each agent its filtered view of the world. The 130% token overhead is the coordination tax. Whether that tax is worth paying depends entirely on what the specialist finds.
I expected the premise to be right in a straightforward way. Multi-agent should beat single-agent.
It does. But only sometimes.
For Bangkok, the coordination tax was maybe fifty cents in extra tokens. The flight savings was nearly six hundred dollars. For Paris, the multi-agent system added cost and time for zero benefit. For Tokyo, the single agent did better.
The paper itself is a framework paper, not a benchmark paper. It gives you a vocabulary for decomposing orchestration into planning, policy, execution, control, state, knowledge, and quality. That decomposition is worth learning regardless of whether you end up building multi-agent or not.
I am not the only one finding this. A Towards Data Science analysis called it “The Multi-Agent Trap”, the tendency to treat every problem as a multi-agent problem when a well-prompted single agent would suffice. GitHub’s engineering blog put it bluntly: most multi-agent workflow failures come down to missing structure. The pattern I saw in my trip planner, structure helps when the search space is large, hurts when it is not appears to be general.
But the performance premise that motivates the framework needs a qualifier. Build multi-agent when the search space is large enough that focused attention finds what divided attention misses. When the cost of overlooking the best option exceeds the cost of looking twice.
For everything else, one agent is enough.
Paper: “The Orchestration of Multi-Agent Systems.” arXiv:2601.13671, January 2026.